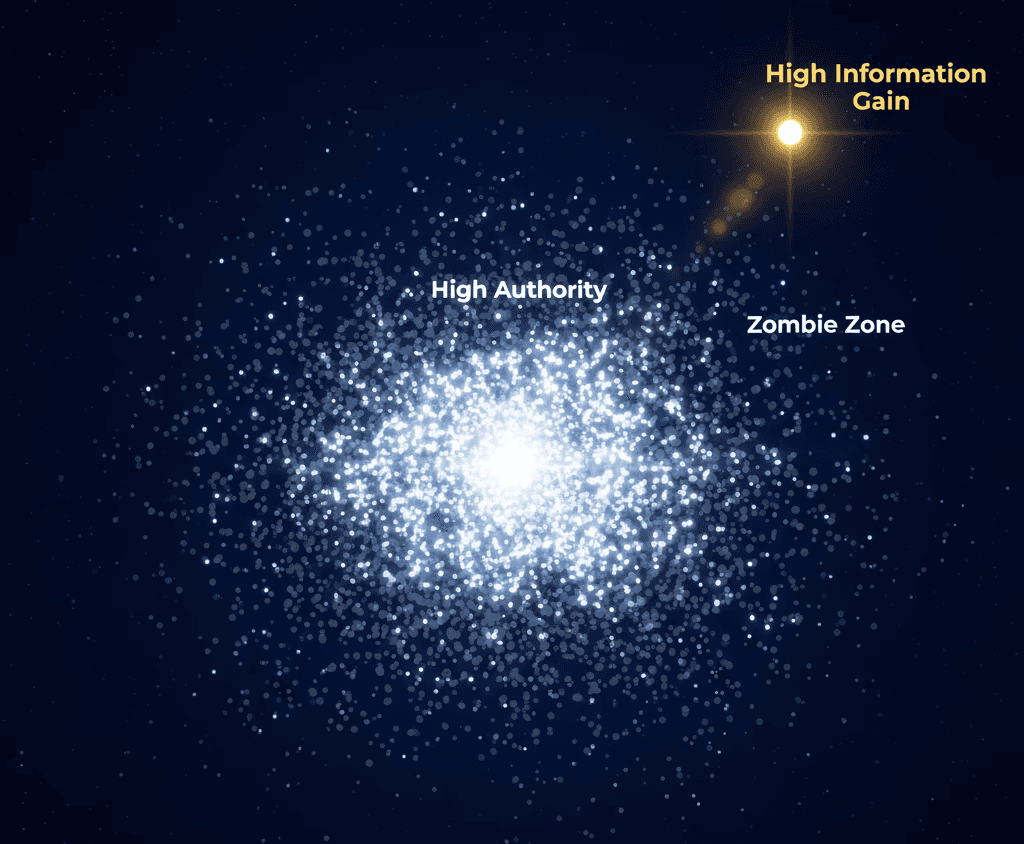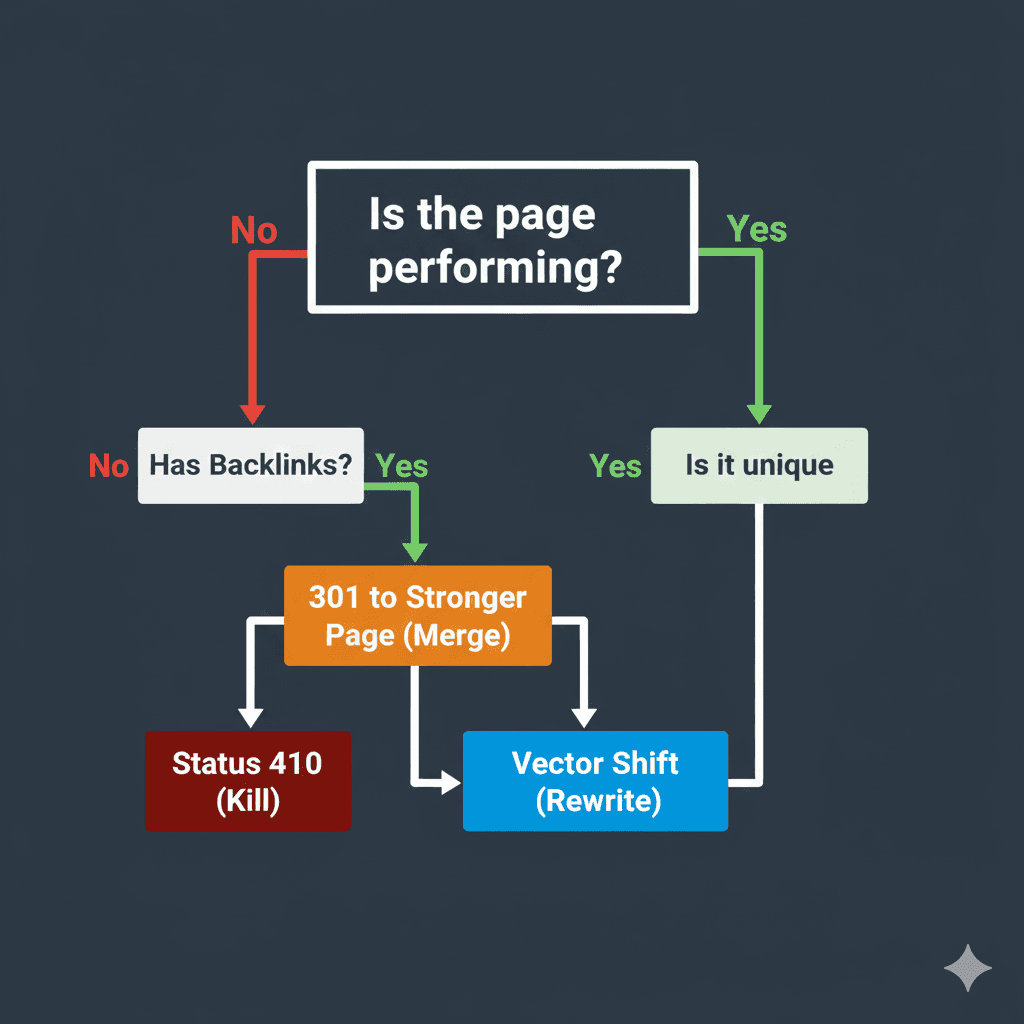
Search engines stopped reading your content like a human years ago. They parse content, consolidate duplicates, and (in many modern retrieval systems) use embeddings to model semantic similarity. If your page ends up functionally equivalent to the market leader, it can get clustered, deduplicated, or treated as the non-canonical version—indexed, technically functional, but practically invisible at selection time [1].
This is not a content problem. It is a proximity problem. To fix it, you must stop editing sentences and start auditing similarity and intent.
Search engines stopped reading your content like a human years ago. They parse content, consolidate duplicates, and (in many modern retrieval systems) use embeddings to model semantic similarity. If your page ends up functionally equivalent to the market leader, it can get clustered, deduplicated, or treated as the non-canonical version—indexed, technically functional, but practically invisible at selection time [1].
This is not a content problem. It is a proximity problem. To fix it, you must stop editing sentences and start auditing similarity and intent.