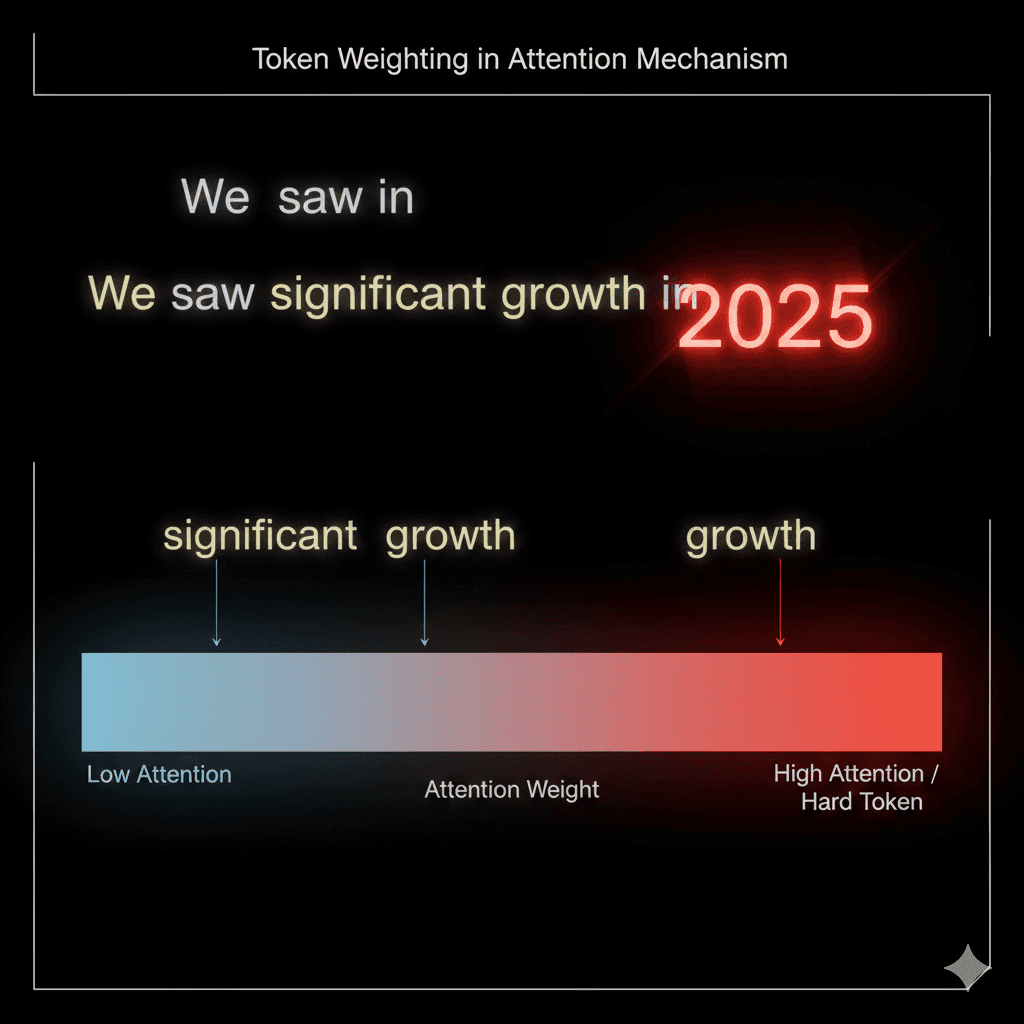
LLMs do not "read" your content the way a human does. They allocate attention. In a Transformer, self-attention determines which tokens influence the model’s internal representation at each step. If your sentence is mostly adjectives, adverbs, and generic filler ("Soft Tokens"), you give the model fewer anchors to lock onto—and your paragraph becomes easier to paraphrase, compress, or skip when an answer system is selecting sources.
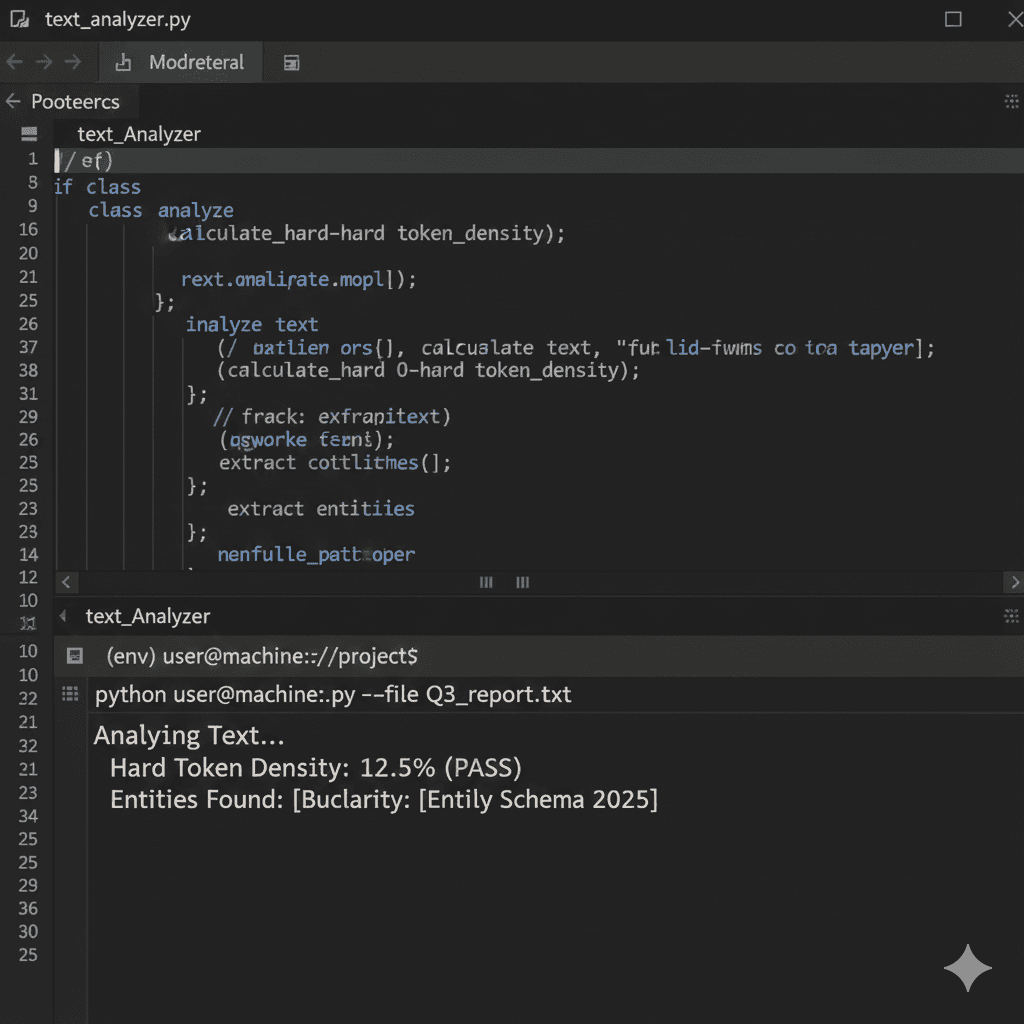
To win the citation, you must stop writing prose and start engineering Entity Density. This is the
"Hard Token" Rewrite Protocol.
LLMs do not "read" your content the way a human does. They allocate attention. In a Transformer, self-attention determines which tokens influence the model’s internal representation at each step. If your sentence is mostly adjectives, adverbs, and generic filler ("Soft Tokens"), you give the model fewer anchors to lock onto—and your paragraph becomes easier to paraphrase, compress, or skip when an answer system is selecting sources.
To win the citation, you must stop writing prose and start engineering Entity Density. This is the
"Hard Token" Rewrite Protocol.